Bonjour à tous,
Depuis maintenant 2 mois, nous travaillons à faire en sorte que vos instances CloudDB (également connues sous le nom «PrivateSQL») gèrent leur mémoire plus intelligemment. Nos tests sont concluants, il est maintenant temps de passer à la production!
L’intervention (planning, avancement, status…) est détaillée ici.
Concrètement ça change quoi?
- **De la mémoire optimisée**. Si les connexions et les requêtes passées à votre instance nécessitent 1.2 Go de RAM et que votre instance n’en fait que 1.0, alors elle se fera «OOM kill». Ce comportement reste le même, mais avant d’en arriver là, le système va maintenant voir si il est possible d’optimiser la mémoire utilisée pour tenter de libérer les pages nécessaires. Nos tests ont montré une baisse significative des «OOM kills» dans de nombreux cas.
- **Des boosts de RAM autorisés**. La majorité des requêtes ont besoin d’aller vite et nécessitent relativement peu de RAM. Certaines autres, plus rares, n’ont pas besoin d’aller vite mais peuvent nécessiter beaucoup de RAM (typiquement, des alter table, des créations d’index, ou des requêtes lancées quotidiennement par des robots qui n’ont pas besoin d’une réponse immédiate). Ce type de requêtes seront maintenant possible jusqu’à un dépassement de 50% de votre RAM. Ces 50% seront plus lents que de la RAM, mais n’entraînent pas d’«OOM kill» et vous permettront de passer les requêtes dont on vient de parler.
À vos retours!
Si vous êtes concernés par les cas ci-dessus et que vous voyez ici que votre instance a été mise à jour, n’hésitez pas à nous envoyer vos retours ici même =)
Amélioration de la gestion de la mémoire sur les CloudDB
Related questions
- [RESOLU] Server unable to read htaccess file, denying access to be safe
 74839
74839  24.11.2019 19:11
24.11.2019 19:11
- Version php 7.0 sur Ovh mais php 5.4.45 sur mon wordpress
69380 10.01.2019 11:14
- Effacer wordpress d'OVH et reinstaller
68591 08.09.2019 21:02
- Comment récupérer son mot de passe phpmyadmin ?
67914 14.11.2016 10:32
- Ne supporte pas FTP sur TLS
65578 11.12.2018 18:48
- Changer la version d'une base de donnée en mutualisé
65315 22.12.2016 11:46
- Résiliation hébergement
65226 27.07.2018 10:39
- Variable upload_max_filesize plus grande que post_max_size
57599 11.06.2017 16:01
- Résiliation hébergement+domaine
56984 11.09.2018 20:28
- Transfert hebergement et domaine .fr entre client OVH ?
55379 21.12.2016 15:10
Ces 2 dernières semaines, nous avons déployé la solution sur 5% de la production. Il s'agit de changements majeurs, c'est pourquoi nous déployons «en mode smooth».
Les interventions se sont bien déroulées, et le résultat est là. On va pouvoir déployer tout ça sur le reste de la production.
Mais avant, nous avons identifié une amélioration, complémentaire aux 2 autres, qui va mettre de l'huile dans les rouages.
On termine nos tests sur cette nouvelle optimisation et on vous tiens au courant très prochainement =)
Bonjour à tous,
2 semaines se sont écoulées. L'amélioration dont je vous ai parlé plus haut a été testée, déployée sur 5% de la prod (exactement les même 5% dont je vous ai parlé il y a 2 semaines), et nous avons laissé tourner. Nous avons maintenant une semaine de recul et pouvons vous dire que le résultat est top: le nombre d'OOM kills a baissé de… 59%! =)
La prochaine étape va consister à déployer la solution en «mode smooth», en plusieurs étapes. Les dates et heures des interventions seront mises à jour dans http://travaux.ovh.net/?do=details&id=44194 la tâche travaux.
Bonjour,
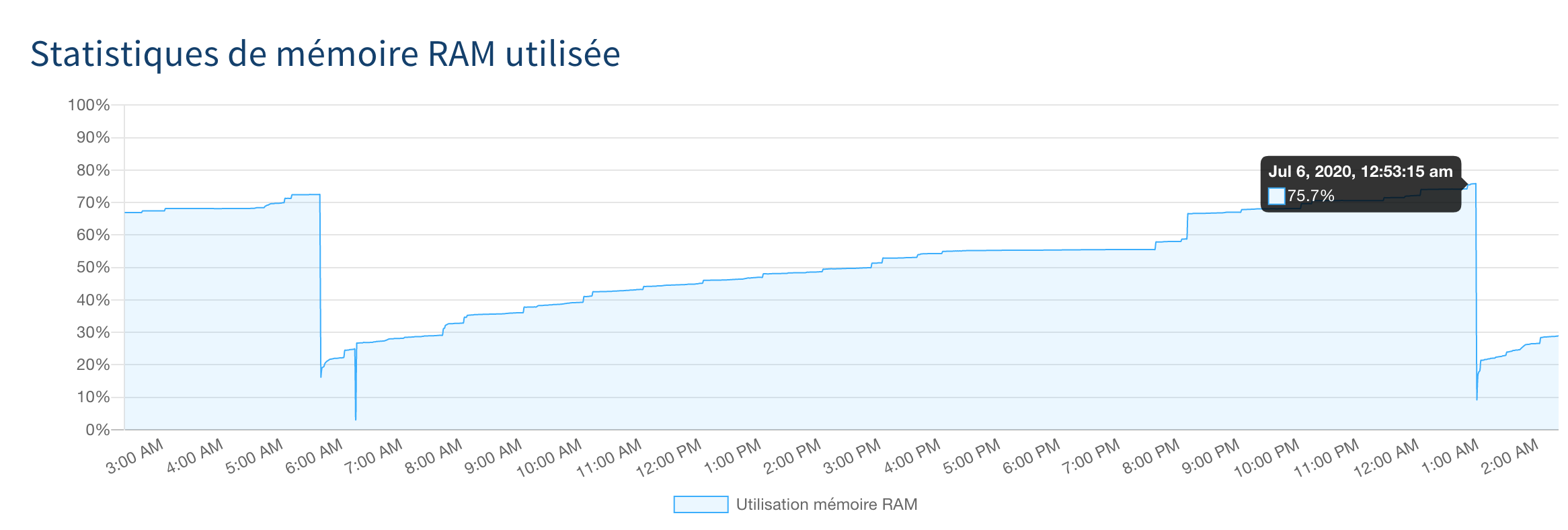
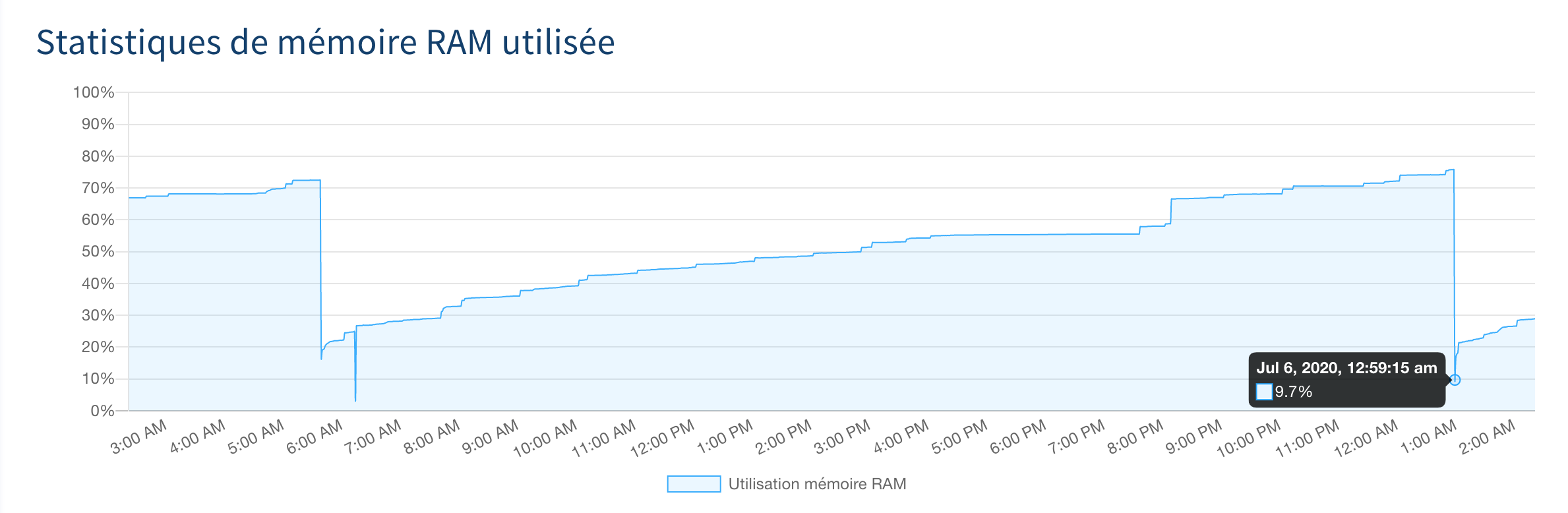
Après avoir attendu quelques semaines que "l'amélioration" soit déployée sur mon SQL Privé, je suis en mesure de vous dire que je ne trouve pas satisfaction, en effet, ce dernier se met à rebooter beaucoup plus qu'avant avec pourtant une ram autour de 75%
Je vous remercie de bien vouloir tenter une correction ou de m'expliquer pourquoi mon SQL Privé redémarre plus souvent qu'avant.
Merci
Bonjour @MICHAELP,
Peux-tu me donner le nom de ton instance que je regarde ce qu'il se passe plus en détail?
Mikaël
Bonjour,
Je vous ai envoyé un message privé, merci
Bien reçu, merci =)
Ton instance a effectivement rebooté. 12 fois en 12 jours. A des heures toujours différentes (c'est de l'UTC):
* 2020-06-25 03:13:24
* 2020-06-26 21:36:16
* 2020-06-28 11:58:32
* 2020-06-29 06:15:22
* 2020-06-30 15:45:22
* 2020-07-03 01:50:57
* 2020-07-04 13:42:04
* 2020-07-05 05:38:47
* 2020-07-06 00:58:57
* 2020-07-06 17:57:39
* 2020-07-06 20:13:47
* 2020-07-06 21:44:30
La bonne nouvelle, c'est que ton instance redémarre proprement, en moins de 5 secondes. Ce qui nous donne une QoS de 99.994%, ce qui est très bien. On continue.
L'autre bonne nouvelle, c'est que tes temps de réponse sont très bons également:
* 0.001s en moyenne pour les selects,
* 0.005s en moyenne pour les update,
* 0.001s en moyenne pour les delete.
Ça veut dire que ton code est bon et efficace, et que ton instance suit… sauf pour ces 12 fois là. On continue.
Du côté de tes données, tout est bien propre également (bravo): tu utilises de l'InnoDB ce qui fait qu'on peut faire tes dumps avec une transaction sans bloquer tout le monde et empiler les connexions (tes dumps se passent à merveille), je ne vois pas de table avec des tailles abérantes, pas de gros blob, des indexes là où il faut. Tout est OK de ce côté là.
Tu sembles donc avoir des besoins **sporadiques** un peu gourmands en RAM. Est-ce que les horaires listés ci-dessus te parlent? Un traitement particulier ou autre à ces horaires (alter, création d'index, dump via PHP, etc)?
2 bonnes nouvelles:
* Comme vu à l'instant, tout semble propre de ton côté (code, stucture des données…), et tes besoins en RAM sont sporadiques. C'est pour moi le cas idéal pour l'optimisation je j'évoque dans ce thread.
* La mise à jour de ton instance est prévue pour demain 2020-07-08, à partir de 23:00 CEST (cf. les dernier commentaire de http://travaux.ovh.net/?do=details&id=44194).
Ce que je te propose donc:
* On attends 3-4 jours le temps pour ton instance d'être mise à jour, et le temps d'avoir un peu de recul pour constater (on croise les doigts) les bénéfices.
* Tu tentes te voir de ton côté quels traitements auraient pu passer à ces heures là.
OK pour toi? =)
Mikaël
C'est ok pour moi, merci. Non, je n'ai pas noté d'actions de masse ou de forte charge.
Peut-être une extension wordpress un peu gourmande, style WP Rocket ou Yoast SEO...
Ça s'annonce pas mal =)
mysql> \s
[…]
Uptime: 1 day 22 hours 2 min 20 sec
(Il s'agit du redémarrage volontaire de ton instance qui a eu lieu lors de l'intervention)
Par contre, les métriques de RAM ne sont plus parlantes =/ La grosse baisse que tu peux voir le 10 juillet à 18:07 UTC n'est PAS un redémarrage de l'instance. Je vois pour trouver une métrique plus probante, voir pour écrire dans un guide ce qu'est exactement cette métrique et comment l'interpréter.
D'accord, j'en profite pour vous demander car cela fait des mois que cela dure.
Que veut dire **11/07/2020 11:16stderr2020-07-11T09:16:16.762448Z 135789 [Note] Got an error reading communication packets** que j'ai dans les logs depuis plusieurs mois ?
mysql> \s
https://community.ovhcloud.com/community/fr/1034-create-index-by-sort-failed?id=community_question&sys_id=5c65f18c851246d01e111c5c94ac5bb7 …]
Uptime: 5 days 16 hours 44 min 36 sec
Je pense qu'on peut dire que le problème est corrigé =)
Ça veut dire que ton client ne ferme pas bien ses connexions. C'est quelque-chose à corriger dans ton code (tu peux voir [ici, quelqu'un d'autre avait le problème et l'a corrigé). À ne pas trop ignorer, entre autres parceque les connexions stagnantes comme ça prennent de la mémoire à rien.
parmi les scripts qui ne ferment pas bien les connexions, il y a un script de supervision OVH ...