Bonjour,
Je viens chercher les conseils et j'espère solutions auprès de personnes plus compétentes que moi au sujet d'un serveur dédié.
### Situation
J'ai très **récemment réinstallé mon serveur Kimsufi** pour passer **sous un Debian 12 bookworm**. J'ai pu réaliser toutes les opérations de réinstallation et configuration avec l'aide d'un proche.
Nous avons d'ailleurs rencontrés plusieurs soucis et difficultés, notamment concernant les DNS et les iptables, qui firewall activé, bloquent beaucoup de choses sans explication, mais ce n'est pas la raison de ma venue.
### Problème
Sans raison apparente, **le serveur devient absolument inaccessible d'une seconde à l'autre**, plus joignable. Confirmé avec l'email des technicien[ne]s d'OVH, m'indiquant que le serveur ne répond plus au ping.
### Pistes explorées
Mon premier reflex est de **chercher des logs système** pour trouver une piste. Tous les logs serveur se trouvent bien dans `/var/log/*`? Avec le grand nombre de fichiers et dossiers ici, où chercher ? J'ai jeté un oeil à `syslog` et `cron.log`, mais je reste dans le flou... S'agit-il d'un crash ? Cela y ressemble, mais comment vérifier.
La seule "solution" actuelle est de reboot à froid la machine, ce qui n'est vraiment pas folichon...
Que faire ?
_Précision à mon sujet, mes compétences sont assez basiques, je me débrouille pour gérer ou installer de nouveaux éléments, mais concernant l'installation et la configuration du système, ou la recherche de panne et debugging (le cas ici), je dois malheureusement admettre être dans l'obscurité._
Un grand merci d'avance pour l'aide ou les conseils potentiellement apportés !
Serveur dédié injoignable d'une seconde à l'autre (crash ?)
Related questions
- Conseil - Proxmox / ZFS
 51303
51303  27.08.2024 09:39
27.08.2024 09:39
- Serveurs OVH blacklistés UCEPROTECT-Level 3
29674 12.04.2021 15:23
- Solution de streaming live
29238 25.08.2017 18:35
- Mon serveur n'est pas en ssl
28780 21.06.2017 15:35
- [Résolu] Problème de connexion à un dédié
26085 15.12.2018 17:42
- Proxmox ou VMWare ?
25969 02.03.2017 22:04
- Conseil Soft Raid vs Hard Raid
25809 13.04.2017 08:49
- Proxmox ip failover problème reseau vers orange
21659 30.11.2020 19:21
- Serveur crash avec ip failover
18359 11.09.2019 14:57
- SoftRaid 3x2To SATA ?
18085 03.01.2019 07:18
Bonjour,
Au bout de combien de temps la machine devient inaccessible ?
Et sans aucune règle Iptables ça donne quoi ?
Bonjour,
le rapport d'intervention sur le serveur indique quoi ?
Cordialement, janus57
Bonjour,
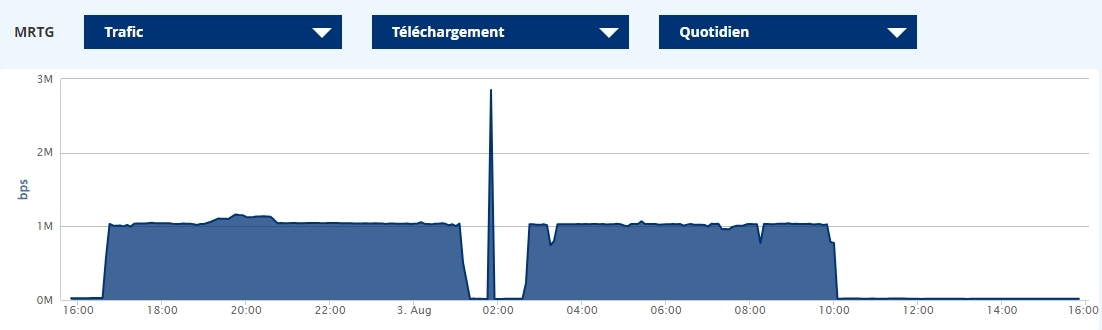
Le délai est assez aléatoire, la première fois c'est survenu une trentaine d'heures plus tard, mais il ne semble pas tenir plus d'à-peu-près un jour.
Actuellement, travaillant de nuit, je commence ma journée et je découvre avec consternation qu'il est encore tombé, plus joignable. Je viens de reboot hard.
Avant-dernière coupure cette nuit vers 01:05, j'étais connecté.
Nouvelle coupure/crash aujourd'hui vers 09:50, d'après mes stats réseau sur mon panel (cf. image ci-dessous).
Cette fois-ci c'est arrivé vraiment plus rapidement.
Effectivement j'ai oublié de préciser, pour l'instant il n'y a aucun firewall, iptables vides justement pour tester et avancer. Le fichier `rules.v4` n'existe tout simplement plus, on l'a backup.
Bonjour,
Côté OVH, voici les infos que j'ai dans leur deuxième email :
> Voici les détails de cette opération :
> Reboot HARD
> Date 2024-08-03 01:28:33 CEST (UTC +02:00), Reboot HARD:
> Voici le détail de l'intervention réalisée:
> Pas d'information à l'écran ("écran noir"). Pas de réponse au clavier.
> Actions entreprises:
> Redémarrage hardware du serveur.
> Résultat:
> Boot OK. Serveur sur 'login'. Ping OK, services démarrés.
Je vous joins, ci besoin, la dernière partie des logs provenant de `syslog` :
https://pastebin.com/eej1a28e
Merci beaucoup pour vous réponses !
Bonjour,
avez-vous fait les tests hardware pour éliminer un problème matériel ?
Cordialement, janus57
Bonjour,
J'avoue ne pas y avoir pensé. Ayant ces comportements depuis la réinstallation, je pense inconsciemment avoir écarté cette piste, pourtant pas impossible dans l'absolu.
Je vais me documenter ce soir, une fois pleinement disponible pour réaliser ce type de test sur ma machine et essayer de trouver quelque-chose de ce côté là !
Merci encore
A dedicated server becoming unreachable from one second to the next could indicate a crash or sudden network issue. Possible causes include hardware failure, software bugs, resource exhaustion (CPU, memory), network disruptions, or security breaches. To diagnose, check server logs, monitor resource usage, and ensure network stability. Immediate actions include rebooting the server, updating software, and running diagnostics to identify and resolve the underlying issue.
Bonjour,
Par contre il y a des choses intéressantes dans vos logs.
Est-ce qu'il serait possible de donner la liste avec date et heure de quand le serveur a arrêté de répondre ?
Car d'après vos logs je dirais que la liste est (si le serveur étais a l'heure) :
- 03/08/2024 à 1h58
- 03/08/2024 à 7h57
Cordialement, janus57
Pouvez-vous fixer votre adresse IP en dur, et évacuer DHCP ?
Bonjour,
Ici c'est pas le problème immédiat car la machine ne répond plus quand le tech OVH est dessus.
Cordialement, janus57
Si le link est en 100 Mbit full duplex il s'agit sans doute d'un kimsufi, donc pas de KVM/IPMI non plus.
Bonjour,
Il a dit qu'il avait un Kimsufi.
Mais là vu les logs avec des traces de shutdown je dirais qu'il y a quelque chose sur la machine.
Par contre vu que c'est un Debian12 il faudrait aussi regarder les logs avec journalctl car mes Debian12 n'ont plus de syslog par défaut si je passe par le netinstaller.
Cordialement, janus57
```
2024-08-03T13:42:28.685637+00:00 ns305546 ifup[394]: ip -6 addr add 2001:41d0:2:8367::1/56 dev enp4s0
2024-08-03T13:42:28.687858+00:00 ns305546 ifup[537]: RTNETLINK answers: Permission denied
[…]
2024-08-03T13:42:28.702890+00:00 ns305546 systemd[1]: networking.service: Main process exited, code=exited, status=1/FAILURE
2024-08-03T13:42:28.765055+00:00 ns305546 systemd[1]: networking.service: Failed with result 'exit-code'.
2024-08-03T13:42:28.765304+00:00 ns305546 systemd[1]: Failed to start networking.service - Raise network interfaces.
```
Bonjour, vous avez désactivé l'IPv6 d'une manière ou d'une autre sans enlever l'IPv6 de `/etc/network/interfaces.d/50-cloud-init`. À cause de ça, au démarrage :
* `networking.service` démarre, il prend une IPv4 en DHCP
* Le serveur tente d'assigner une IPv6 mais ça plante, on a l'erreur vue dans le log concernant l'IPv6, le service passe en erreur
* Le client DHCP se fait tuer
* 24 heures plus tard (le temps du bail DHCP), l'IPv4 obtenue en DHCP expire et le client DHCP est mort donc vous perdez le réseau
C'est un problème assez classique sous Debian. Je vous conseille simplement d'enlever la configuration IPv6 si vous n'en avez plus besoin.
Bonjour @le_sbraz ,
Merci pour cette analyse.
Est-ce que par hasard tous les problèmes déjà vus ici concernant des lease DHCP qui ne se renouvellent pas (avec perte de connectivité évidemment) seraient-ils dus à ce problème d'IPv6 ???
Just my 2 €cents
Une grande partie, oui :) C'était lié à l'autoconfiguration IPv6
Ça a été corrigé par :
https://salsa.debian.org/debian/ifupdown/-/commit/fe9fb5882ab5d238122d986454b0d156477bc8d0
https://salsa.debian.org/debian/ifupdown/-/commit/3fb794b2dc1f16da09409522826142ef5e226ddc
Aujourd'hui, quand le problème se produit, c'est que le client a cassé d'une manière ou d'une autre la configuration réseau (quand les modifications sont faites _après_ la configuration DHCP).
A priori, ce genre de problème ne se produit pas avec Netplan qui est quand même plus robuste et refuse complètement de démarrer. Donc sur nos installations Debian 12, on n'aura jamais ce comportement (ce n'est pas le cas d'@AlexandreDBP qui semble avoir upgradé une Debian 11 utilisant encore ifupdown) .
Sur un proxmox installé le 11 février de cette année à partir de votre distribution, c'est bien Debian12 et /etc/network/interfaces (ce qui m'arrange car je n'ai pas encore viré ma cuti !)
Bonjour,
Proxmox n'utilise pas netplan c'est peut être le pourquoi du comment.
Cordialement, janus57
En effet alors là c'est encore différent, Proxmox utilise ifupdown2 ! C'est une réécriture de ifupdown en Python. À ne pas confondre avec ifupdown-**ng** utilisé par Alpine :D
Bonjour,
Merci pour toutes vos réponses aujourd'hui, nous allons explorer chaque message avec mon collègue cette nuit.
Il y a une piste qui m'intéresse fortement, celle de votre message le_sbraz, concernant l'IPv6, nous allons également essayer ça après une nouvelle vérification matériel et possiblement de réinstaller une image de Debian 12 originale manuellement.
Pour information, il est de nouveau tombé il y a 30mn, à 50h55,
Le 4 aout à ~19h50,
Le 3 août à ~01h00,
Le 2 août à ~01h00.
...
Ce que m'expliquais la personne qui m'assiste fortement dans ce dossier, c'est qu'il n'y a qui rien dans les logs, donc un crash ou une panne si critique que le système n'a pas le temps d'enregistrer quoi que ce soit.
Ce serveur dédié, je l'ai déjà depuis une dizaine d'années maintenant. C'est quand même étrange, bien que toujours possible bien évidemment, qu'il s'agisse d'une panne côté hardware au moment même exact où on réinstalle tout au propre et à jour... Le check de ce soir nous le dira.
Un grand merci d'avoir pris le temps d'examiner ces logs de l'enfer...
Je vais bosser dessus cette nuit et vous tiens au courant !
Au démarrage, faites un `systemctl --failed`. Si vous avez des services failed, comme on voit que c'est le cas pour `networking.service`, il faut corriger leur configuration.
> c'est qu'il n'y a qui rien dans les logs
Je pense qu'il n'y a rien dans les logs car l'IP expire sans rien dire, vous pouvez voir dans `ip a` son `valid_lft`.
Je ne suis pas convaincu qu'il y ait un crash. Dans le pastebin, vous mettez les logs à partir de 2024-08-03 02:41 CEST. Avez-vous les logs avant ça ? Je suppose que vous devriez tout de même avoir des logs après 2024-08-03 01:10 CEST, heure à laquelle le serveur a arrêté de pinger, ce qui confirmerait que c'est une perte de réseau et non un crash.
> possiblement de réinstaller une image de Debian 12 originale manuellement
Je comprends mieux pourquoi vous êtes passé par une upgrade de Debian 11 à 12 : on ne propose pas Debian 12 directement sur votre serveur. C'est parce que c'est une référence très ancienne. Le plus simple pour vous serait certainement de réinstaller en utilisant l'OS BYOI avec l'image de base Debian 12 https://cdimage.debian.org/cdimage/cloud/bookworm/latest/debian-12-generic-amd64.qcow2
Bonjour,
Effectivement comme attendu, networking.service failed, on va faire différemment.
Pour les logs, j'ai pris une plage comprenant deux incidents car le fichier total a +20000 lignes, je ne voulais pas assommer avec un tel fichier, d'où le "court" extrait par rapport à l'original.
En faisant un `ip a`, j'ai bien `valid_lft forever preferred_lft forever`, donc l'IP n'expire par en tout cas d'ici ?
Par contre concernant le dernier point, sur la version du système, je ne suis pas sûr de comprendre. Debian 12 s'agit de la version stable la plus récente, après 11. Comment peut-il donc être une référence très ancienne étant sortie après le 11, je pense avoir mal compris.
Sinon c'est effectivement ce qui va être fait, réinstallation manuelle en upload l'image officielle de Debian 12. Merci pour le lien d'ailleurs au passage :)
Bonjour,
non c'est de votre serveur physique qu'il est question de son ancienneté.
Pour le coup cela peut être aussi intéressant de prendre une nouvelle offre avec un serveur (et donc hardware) plus récent.
Cordialement, janus57
Je dirais que oui. En tout cas, assurez-vous bien d'avoir un service `networking.service` en statut OK :)
Et pour la référence, je parlais bien du hardware comme l'indique @janus57.
Ah d'accord je comprends mieux ! Donc oui effectivement, l'ayant depuis 2015, c'est assez vrai !
Mais ceci m'apporte une question supplémentaire : est-il possible de changer d'offre donc de serveur, tout en gardant la même adresse IP, obligatoire dans mon cas ? Ou sinon, changer de serveur sans modifier l'offre ?
Une offre/serveur plus à jour m'intéresserait, ne serait-ce que pour revoir les budgets, mais s'il faut attendre une disponibilité comme au tout début et changer d'IP, ça élimine cette possibilité immédiatement malheureusement.
Impec donc soit on fixe ça, soit on part sur une réinstallation manuelle complète déjà, ce qui semble plus cette deuxième option que l'on envisage pour le moment. Je vais voir s'il est possible de faire un gros point sur toutes ces options et possibilités cette nuit avec la personne que je peux avoir, s'il est présent et je vous tiens informé, comme d'habitude !
Merci encore pour ces infos !
Bonjour,
non, sauf si vous avez une IP FailOver mais c'est pas possible sur Kimsufi.
non plus
si vous avez des contrainte opérationnel je pense que choisir Kimsufi à la base est une mauvaise idée, vu ce que vous dite (IP qui ne doit pas changer) pour moi vous devriez être plus sur la gamme SYS.
Cordialement, janus57
Le correctif devrait vraiment être simple : enlever les lignes concernant l'IPv6 de `/etc/network/interfaces.d/50-cloud-init`. Ça serait dommage de réinstaller pour si peu.
Ok ça a le mérite d'être clair et rapide :) Au moins ça écarte cela de suite ! Merci pour l'éclaircissement sur ces points, cela faisait quelques-années que j'y pensais quelquefois.
Effectivement, ça aurait pu être étudié avant de partir sur cette offre, mais il y a dix ans c'était bien différent de mon côté. A l'origine de l'origine, c'était le technicien de ma boîte qui m'avait conseillé cette offre pour moi, pour le perso. Mais j'ai eu plusieurs surprises avec lui par la suite...
Donc en tous les cas, on reste sur ce KS au moins !
Je vais essayer ça en détail tout à l'heure, une fois posé pour la nuit sur mon PC portable au travail. J'ai fait un rapide coup d'oeil au fichier, ayant +300 lignes, je vais devoir chercher un peu j'imagine.
Merci bien, je vais regarder ça :)
Tout ce qui est sous `iface enp4s0 inet6 static` et inclus peut partir, il suffit de conserver
```text
auto lo
iface lo inet loopback
auto enp4s0
iface enp4s0 inet dhcp
accept_ra 0
```
Ok fichier corrigé de mon côté ! Voici ce qu'il reste comme contenu dans ce dernier :
[details=50-cloud-init]
auto lo
iface lo inet loopback
auto enp4s0
iface enp4s0 inet static
address 91.121.220.103
gateway 91.121.220.254
netmask 255.255.255.0
broadcast 91.121.220.255
accept_ra 0 dns
dns-nameservers 8.8.8.8 8.8.4.4
[/details]
Serveur manuellement redémarré proprement à 22h23.
Par ailleurs, voici également le résultat d'un `systemctl --failed` :
`UNIT LOAD ACTIVE SUB DESCRIPTION
0 loaded units listed.`
Tous ces soucis venaient "simplement" de cette mauvaise configuration ? En tout cas c'est fait, je vais voir s'il tient et si tout fonctionne normalement !
Merci bien, je vous répond dès qu'il y a du nouveau !
> Tous ces soucis venaient "simplement" de cette mauvaise configuration ?
C'est l'impression que j'ai. Vous n'êtes pas le premier à vous faire avoir par la conf réseau Debian et le combo DHCP IPv4 + IPv6 non fonctionnelle :)
Et si vous voulez éviter d'envoyer vos requêtes DNS à Google, notre serveur est `213.186.33.99`. C'est celui qui est défini quand le serveur est en DHCP.
Effectivement c'est assez embêtant... Mais bon au moins je gagne en experience on va dire, regarde le bon côté des choses.
Concernant les crashes, c'est quand même étrange car jusqu'à maintenant, ils sont survenus à une période de temps assez aléatoire, entre deux jours max et jusqu'à deux fois en une journée. De plus, si c'était un problème de configuration réseau, les techniciens d'OVH ne m'indiqueraient pas "_Pas d'information à l'écran ("écran noir"). Pas de réponse au clavier._"
Donc il doit encore y avoir le sujet initial je présume, j'attends le résultat des tests hardware et de voir sur 24/36h s'il tient debout
Bonjour,
Petit point résultats de tous les tests matériels :
https://1drv.ms/f/s!AqLKzi0WwsMBg9lYmtZ81MVgrnfovw
Il y a clairement un problème sur la RAM non ?
Si oui, j'imagine devoir ouvrir un ticket avec le support officiel d'OVH pour signaler ce défaut et procéder à sa résolution ?
Curieux d'avoir vos avis sur ces résultats !
Nous avons validé le projet de réinstaller la machine via une image envoyée et configurée totalement de notre côté, cependant pour cela et étant absolument en dehors de mes compétences, j'attends d'avoir la personne qui m'assiste pour ces opérations en direct, normalement vendredi.
Je vous tiens informé !
En effet, ce n'est pas rassurant. Je pense que vous devriez ouvrir un ticket avec le résultat de `memtester`. Je ne pense pas qu'il soit nécessaire de relancer une installation.
Merci pour la réponse rapide !
Je vais donc contacter OVH avec le memtest joint, on va voir ça !
Déjà un vrai souci identifié...
### Petit point news après contact avec le support
Après avoir ouvert un ticket aujourd'hui, une intervention des techniciens a été effectuée. Cependant et à ma grande surprise, ils n'ont absolument pas fait ce qui a été évoqué, pas de changement de RAM, ni même de reboot, globalement rien hormis un rapide check... Voici ce que j'ai eu en retour :
> Détail de l'opération:
> Check Hardware & Cooling OK
> 2024-08-05 21:33 Post Intervention Check SUCCESS
> 2024-08-05 21:38 Post Intervention Bench SUCCESS
Par ailleurs, après un nouveau memtest de mon côté après la supposée intervention, il y a davantage d'erreurs qu'avant (résultats disponible ci-dessous). https://1drv.ms/t/s!AqLKzi0WwsMBg9l3mtZ81MVgrnfovw
J'ai également signalé que le HDD était assez fatigué, dans les normes mais il a bien vécu visiblement. Aucun retour sur ce point.
J'attends à présent la réponse au ticket.
Sinon, avec un petit traceroute au passage, je me suis rendu compte qu'il y avait pas mal de perte après leur réseau.
`mtr google.com` : https://1drv.ms/t/s!AqLKzi0WwsMBg9l1zqGhGuMyk89tqw?e=CqcasC
Bonjour,
les disque ne sont pas changés en préventif, uniquement quand ils HS/defectueux
RAS => 0% de perte sur la cible donc tout va bien
Cordialement, janus57
D'acc, donc obligé d'attendre une perte potentielle de données.
En tout ce n'est pas le sujet original, pour la RAM c'est plus surprenant en tout cas...
Merci pour la confirmation :)
Bonjour,
normalement vous avez vos backups pour vous prémunir de ce cas.
Et si votre serveur a un seule disque cela va également vous faire une interruption de service total (comparé a un serveur qui a minimum 2 disques avec du RAID pour continuer à fonctionner - d'où le fait qu'un kimsufi pour de la prod c'est pas recommandé).
Cordialement, janus57
Bonjour,
Effectivement j'ai toujours eu des backups, c'est une habitude et une précaution que j'ai toujours eu pour toutes mes données, donc hormis le dérangement, ça devrait aller.
C'est en 2to sans RAID dans notre cas, donc backup à la main en cas de souci ! C'est sûr qu'aujourd'hui, sans les mauvais conseils de mon premier tech à l'époque, je serais plus parti sur un SoYouStart de toute évidence...
J'ai eu une nouvelle réponse du support également, me confirmant que la RAM et le HDD vont être changés. J'espère que cela sera réellement effectué cette fois-ci, surtout avant le week-end...
Comme d'habitude je vous tiens informé jusqu'à la résolution du problème initial !
Merci pour vos réponses, conseils et informations utiles
2 To (si le disque est plein) à restaurer sur une connexion de 100 mégabits, ça fait mal aussi.J'ai aussi un KS de ce genre (un intel Atom et 2 To) il est là pour recevoir le second backup d'autres serveurs, au moyen de rsync.
C'est ça, il n'était pas plein à 100% bien sûr, mais ça fait tout de même mal à renvoyer après réinstallation !
Bonjour,
Un petit retour pour après les changements hardware d'OVH puis la réinstallation de notre côté. Après le changement de la RAM défectueuse, puis un nouveau disque dur, on a manuellement installé Debian 12 avec BYOI, configuré proprement.
Tout fonctionne à présent sans aucun souci ! Plus de souci logiciel, plus de problème réseau, plus de de surcouche au système, enfin un gros dossier qui se ferme...
Un grand et sincère merci pour l'aide et les conseils que vous avez pu m'apporter !
Excellente continuation :)